ASPEN Breaking Operator Barriers for Efficient Parallel Execution of Deep Neural Networks
简介
这篇工作提出了一个叫做 opportunistic parallelism 的概念。其基于以下的观察:大部分的 DNN 加速库在计算矩阵乘法时,会将大矩阵拆分为小矩阵(tile)来对齐寄存器大小提高计算效率。拆分之后就有更多的并行机会了,如下图(b)(d)所示,左右两侧的张量仅依赖一个父节点,不用等 operator2 计算完成 operator3 的部分就可以同时计算。
这里的拆分是指拆分张量(和张量并行类似,但是文章是基于多核CPU去做的,paper中也只讨论了CPU计算,这种模式感觉和张量并行是相同的,不太确定张量并行是否有这样的工作模式)
limitations: 1.只描述了单机 CPU 怎么做 2. 从文章来看只能用于静态计算图构建(也不支持训练)
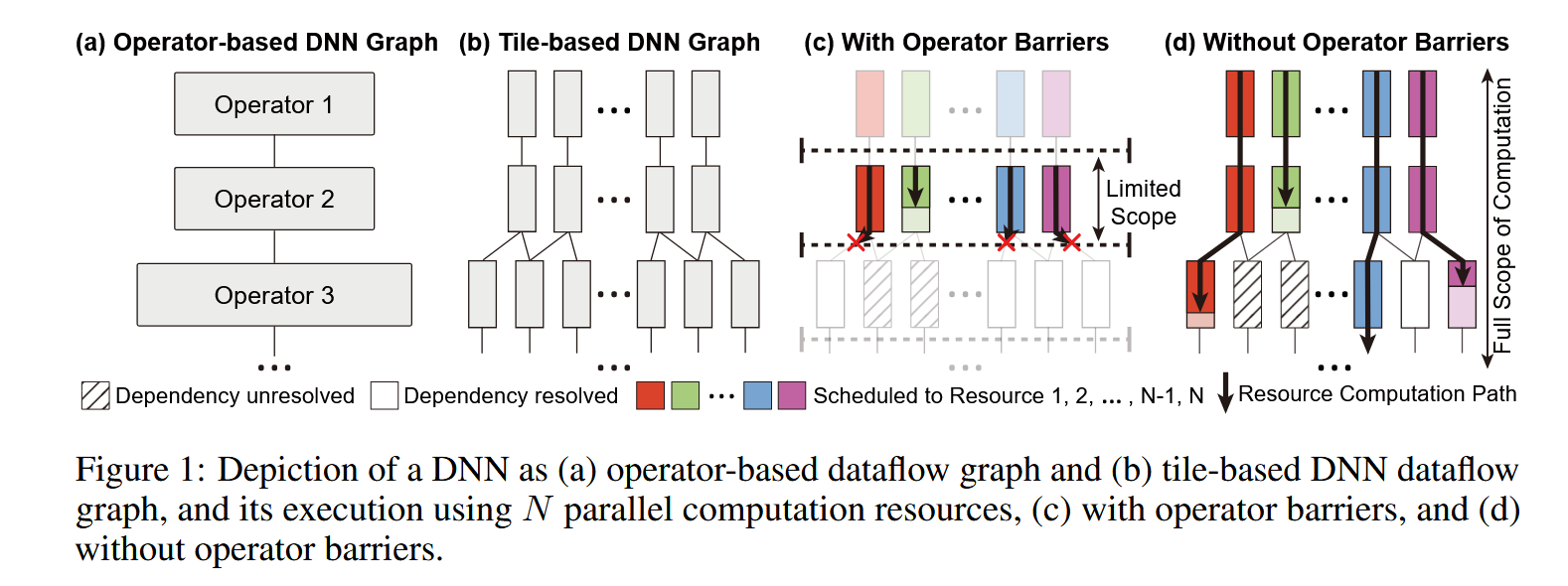
要实现上述机会要解决以下几个问题:1)如何表示计算图(一起的计算图是算子单位,现在需要用 tile 单位来重新表示)2)怎么去调度,计算先后顺序如何保证 (这里原文列了3点后两点我认为都是在解决调度问题)
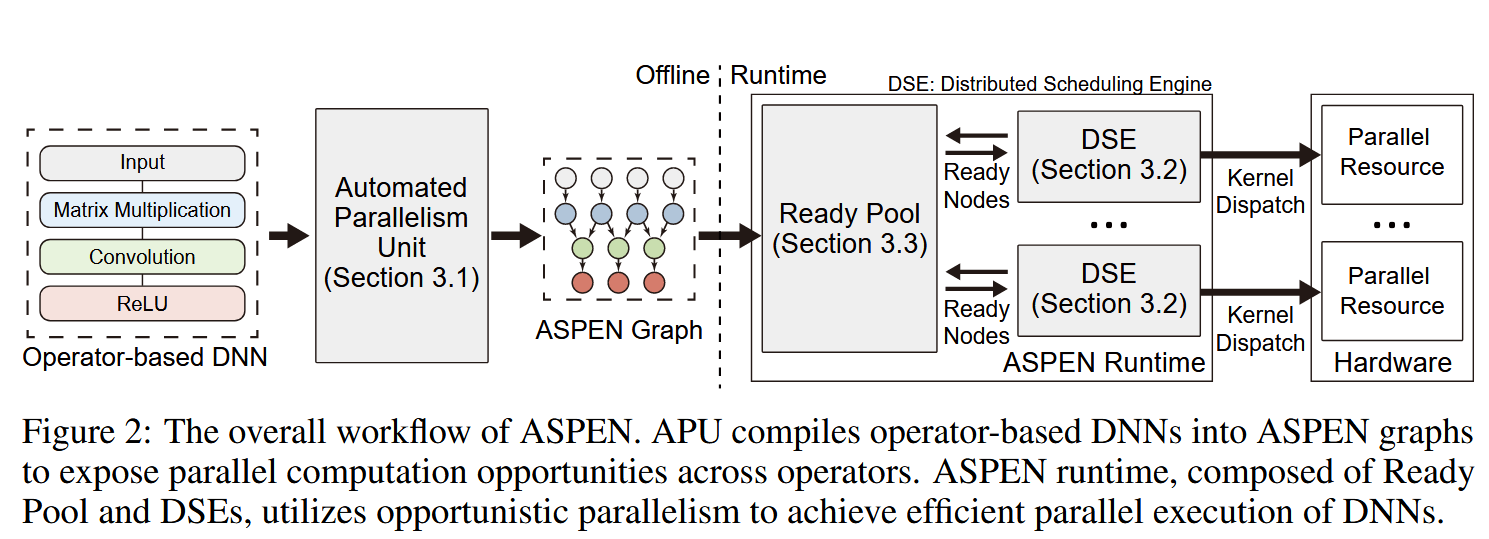
作者主张的工作流程如下:1. APU(Automated Parallelism Unit) 先将计算图转为 ASPEN 计算图,也即是切了张量之后的计算图 2. DSE(Distributed Schedulin Engine) 每个资源一个(CPU的话感觉就是绑定到不一样的core,GPU用不一样的stream这样)3. Ready Pool 看哪些 task 的没依赖了从里面取出来执行就行了。
APU - Automated Parallelism Unit

这个思路比较简单,就是先把矩阵切成很多的 tiles 然后,把输入和输出依赖对应。根据设备信息合并矩阵大小(对齐寄存器大小)。
Ready Pool / DSE - Distributed Scheduling Engine
一句话概括就是一个资源(文章仅说了用 CPU,CPU核、或CUDA的stream,如果能拓展到集群可以是一台设备)一个 DSE 来负责执行,DSE 中 Ready Pool 取一个没有依赖的任务执行,然后反馈给 ready pool 刷新下依赖状态。